Abstract
To substantially enhance robot intelligence, there is a pressing need to develop a large model that enables general-purpose robots to proficiently undertake a broad spectrum of manipulation tasks, akin to the versatile task-planning ability exhibited by LLMs. The vast diversity in objects, robots, and manipulation tasks presents huge challenges. Our work introduces a comprehensive framework to develop a foundation model for general robotic manipulation that formalizes a manipulation task as contact synthesis. Specifically, our model takes as input object and robot manipulator point clouds, object physical attributes, target motions, and manipulation region masks. It outputs contact points on the object and associated contact forces or post-contact motions for robots to achieve the desired manipulation task. We perform extensive experiments both in the simulation and real-world settings, manipulating articulated rigid, rigid, and deformable objects that vary in dimensionality, ranging from one-dimensional objects like ropes to two-dimensional objects like cloth and extending to three-dimensional objects such as plasticine. Our model achieves average success rates of around 90%.
Video Introduction. |
Pipeline Overview
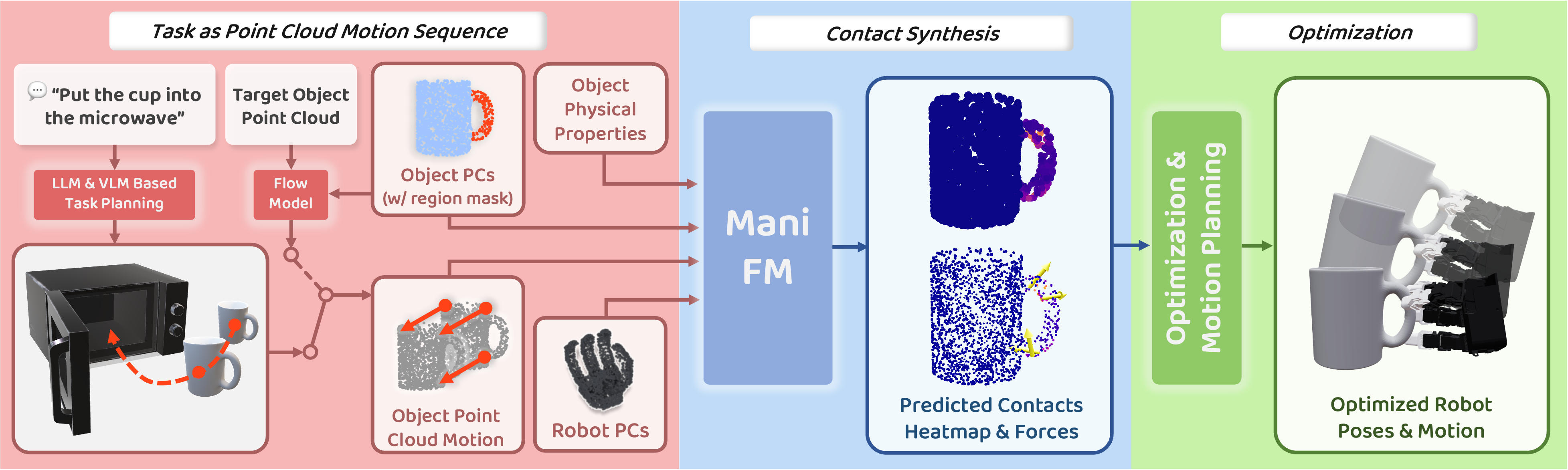
The pipeline of our Manifoundation model. Left: we decompose a manipulation task to a sequence of object point cloud motions from either VLM-based planning or a flow model. Middle: we train a ManiFoundation network to predict the contact point and force heatmap for each motion of the sequence. Right: we acquire the robot pose for execution based on optimization with the initial results from the contact point and force heatmaps.
Network Architecture
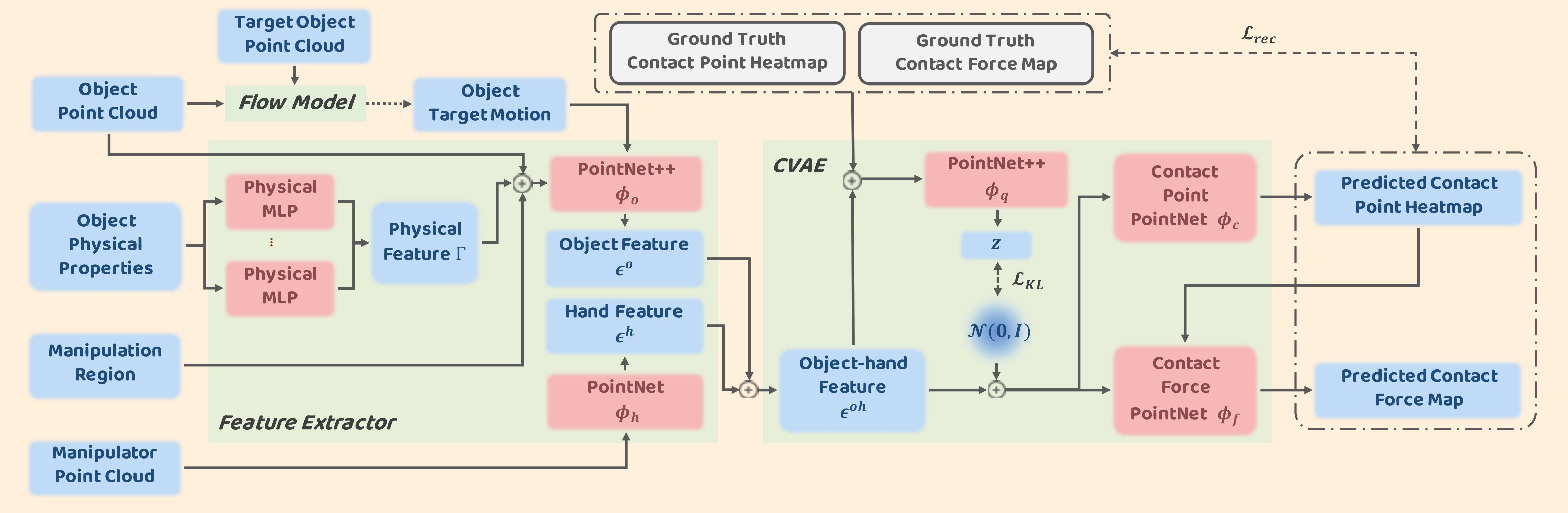
Overview of our ManiFoundation Network. The feature extractor module incorporates the information from both object and robot point clouds, and the CVAE module generates the contact point and force maps on the given object.
Dataset


We create a large-scale comprehensive annotated dataset that includes articulated/rigid objects and deformable objects in 1D/2D/3D forms. Each training example contains the input of our network: oriented object point cloud, target point cloud, target motion, object physical properties, manipulation region mask, manipulator point cloud, and the ground truth contact point heatmap.
3D Visualization
We visualize some object results of using ManiFoundation Model in 3D. The objects include milk box, toothbrush, toothpaste, fridge door, cup, and plate. We visualize their results on LeapHand.
The visualization includes the original object, object motion, predicted heatmap and forcemap, and hand optimized result.
Milk Box
Toothbrush
Toothpaste
Fridge Door
Cup
Plate
Multi-modal Solution Visualization
We visualize some multi-modal solutions of using ManiFoundation Model for manipulating rigid bodies. The visualized tasks include rotating a knob, tilting a book, open a microwave door, and lift a plane. The visualization includes the original object, object motion, multiple proposals of predicted heatmap and forcemap.
Rotate the Knob
Tilt the Book
Lift the Plate
Push the Microwave Door
Pred. & Opt. with Manipulation Regions
We visualize some results of using ManiFoundation Model for manipulating rigid bodies with spefified manipulation region. The visualized tasks include tilting a kettle, and lifting the cup. Our visualization includes the input point cloud of the object, object motion, predicted heatmap and forcemap, and optimized hand configuration.
Tilting the Kettle
Lifting the Cup
Deformable Objects Visualization
We visualize some solutions of using ManiFoundation Model for manipulating deformable objects likt rope and clothes.
BibTeX
@misc{xu2024manifoundation,
title={ManiFoundation Model for General-Purpose Robotic Manipulation of Contact Synthesis with Arbitrary Objects and Robots},
author={Zhixuan Xu and Chongkai Gao and Zixuan Liu and Gang Yang and Chenrui Tie and Haozhuo Zheng and Haoyu Zhou and Weikun Peng and Debang Wang and Tianyi Chen and Zhouliang Yu and Lin Shao},
year={2024},
eprint={2405.06964},
archivePrefix={arXiv},
primaryClass={cs.RO}
}